An Empirical Investigation into the Nature and Degree of Nominality – Alex Carr
For an enlarged version, click on the poster or download the file:
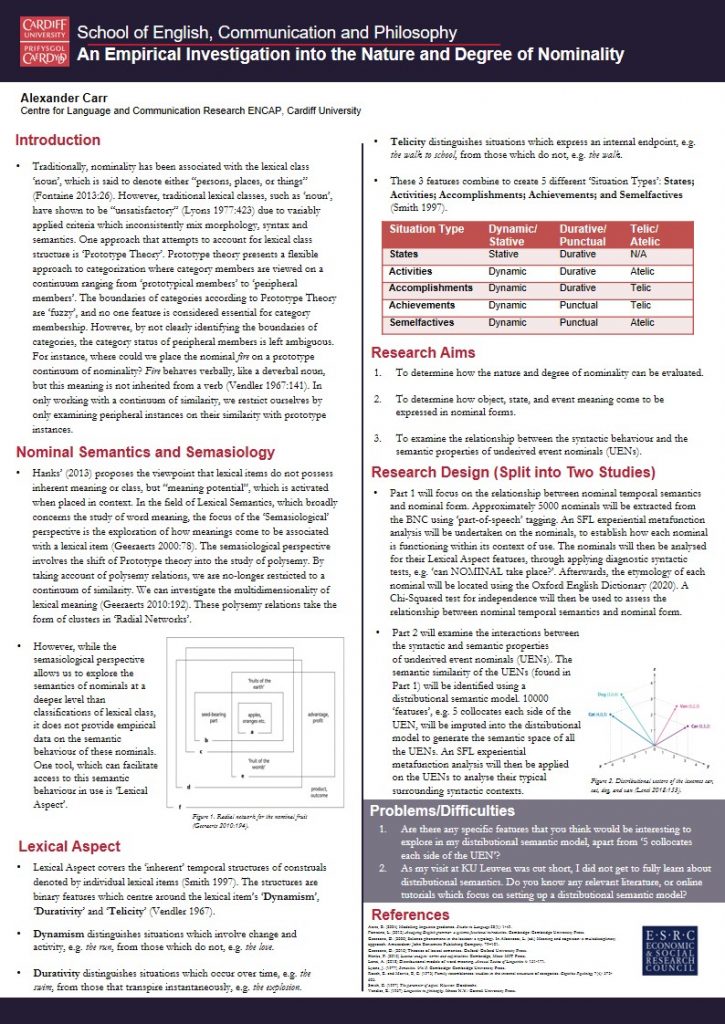
Problems/Difficulties:
1.Are there any specific features that you think would be interesting to explore in my distributional semantic model, apart from ‘5 collocates each side of the UEN’?
2.As my visit at KU Leuven was cut short, I did not get to fully learn about distributional semantics. Do you know any relevant literature, or online tutorials which focus on setting up a distributional semantic model?